

Was MCP a mistake? The internet weighs in
Anthropic released a new blog post about fixing MCP's problems with code execution, but many internet commentators argued it only highlights that MCP is fundamentally flawed and unnecessary.


MCP is pissing a lot of people off, which may seem surprising for a software protocol. Earlier this month, Anthropic published a blog post on how to make MCP 98.7% more token efficient with code execution. You’d think this would be a good thing, but for large parts of the community, they don’t see “MCP with code execution” as an improvement of MCP as much as proof that MCP never should have existed at all. And honestly? They’re making some pretty strong points.
First, let’s cover the problems Anthropic is highlighting in their blog post.
Two Problems with MCP that Anthropic Highlights
The first problem is that MCP tools eat up a lot of context, which both limits how much additional context you can fit into your window for actually doing things, but also raises your LLM usage and cost. As I tweeted earlier, using just two MCP tools, I already eat up 20% of my context window, before I’ve even done anything!
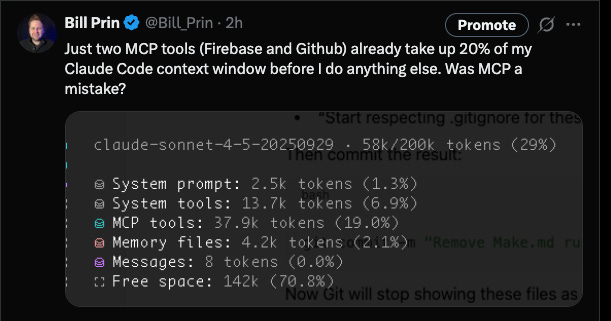
The second problem Anthropic highlights is that MCP tools are not composable. Anthropic gives the example of pulling a transcript from Google Drive and uploading that transcript to Salesforce. The problem is that in a real coding environment, you could store that long transcript in a variable, but since MCP has no concept of variables, the entire transcript is passed between the two different tools as text. If the transcript is long, this could eat up a ton of tokens.
Anthropic’s Solution - And Why The Community Is Skeptical
Anthropic’s proposed solution is to make MCP more code-oriented. To solve the first problem that MCP tools take up too much context, the proposed idea is for MCP tools to expose a much smaller surface area meant only to discover options, and have the MCP client query that to determine what’s available as necessary.
To solve the second problem of composability, the proposed solution is to have MCP clients use the discovered MCP surface areas and write code to interact with it. In our example above including Google Drive and Salesforce, you can imagine the MCP client writing a short script with a variable to capture the transcript, and now the context has a short variable name instead of a long transcript.
If you don’t think too hard about it, this all sounds appealing. MCP has problems, Anthropic has proposed ways to improve MCP to fix those problems. But there’s a bigger picture issue - if LLMs can write code, why do we need MCP at all?
Steve Krouse took to Twitter to make the following points:
LLMs were bad at writing JSON
So OpenAI asked us to write good JSON schemas & OpenAPI specs
But LLMs sucked at tool calling, so it didn’t matter. OpenAPI specs were too long, so everyone wrote custom subsets
Then LLMs got good at tool calling (yay!) but everyone had to integrate differently with every LLM
Then MCP comes along and promises a write-once-integrate everywhere story.
….
Now this next part sounds like a joke, but it’s not. They generate a TypeScript SDK based on the MCP server, and then ask the LLM to write code using that SDK
Are you kidding me? After all this, we want the LLM to use the SAME EXACT INTERFACE that human programmers use?
Let me paraphrase Steve’s point here: a big reason that MCP came to being in the first place was because LLMs were not very reliable at writing code to an API spec. Now they are more reliable at writing code to an API spec, so much that Anthropic is suggesting that MCP should generate a spec and MCP clients should write code to it. But that raises the question - why not just use the original API specs that humans are using, such as those generated by tools like OpenAPI?
In other words: we started with OpenAPI specs, abandoned them for MCP because LLMs couldn’t handle them, and now that LLMs can handle specs again, we’re... generating specs from MCP. We’ve gone full circle.
Theo (t3.gg) Piles on the Hatred
Theo Browne, one of the biggest and most influential YouTubers in the developer space with over 480k subscribers, jumped into the criticism with his own video Anthropic admits that MCP sucks that has over 100k views. This video contained a hilarious amount of anger towards a software protocol, including the following quotes:
“How the fuck can you pretend that MCP is the right standard when doing a shitty code gen solution instead saves you 99% of the wasted bullshit? That is so funny to me. The creators of MCP are sitting here and telling us that writing shit TypeScript code is 99% more effective than using their spec as they wrote it. This is so amusing to me.”
and
This is what happens when we let these LLM people make the things that we have to use as devs. Devs should be defining what devs use. And if you don’t let them do that, then you’ll end up realizing they were right all along.
Are Skills Just MCP But Better?
I wanted to make this post somewhat two-sided on this debate, but honestly, I found the anti-MCP points much more compelling. Still, MCP solves more than one problem. The first is how the LLM uses a third-party tool, which we’ve already seen argued, does not require MCP. The second is how MCP discovers what tools is even possible for it to call. We might not want to clutter up our context window with every possible GitHub API call we could make, but we do want a way for the LLM to reliably know how to use the GitHub API properly when we need it, ideally with some examples.
Coincidentally, shortly before Anthropic wrote their own blog post addressing MCP’s problems, Mario Zechner wrote his own MCP-alternative solution in a blog post titled What if you don’t need MCP at all? . He was even prescient enough to highlight the exact same problems that Anthropic did, two days before their own post!
Unfortunately, many of the most popular MCP servers are inefficient for a specific task. They need to cover all bases, which means they provide large numbers of tools with lengthy descriptions, consuming significant context.
…
MCP servers also aren’t composable. Results returned by an MCP server have to go through the agent’s context to be persisted to disk or combined with other results.
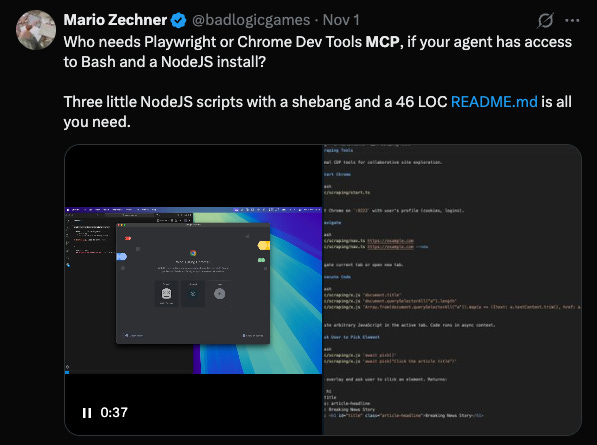
Mario’s alternative approach to tool calling is to create a README that references certain scripts (the tools he needs to use), as well as examples on how to use them. He specifically picks the “MCP enabling the agent to see the browser window during web dev” as an example, since it feels like it should be one of the more complex use-cases of MCP, but he easily replaces it with a few scripts.
Of course, if we’re replacing MCP with “small markdown files that explain how to do a task”, that sounds an awful lot like the recently announced Claude Skills. And Mario specifically calls out that Claude Skills are aligned with his approach, although he still prefers doing it his way for even greater control.
But it certainly feels like Claude Skills could fix many of MCP’s problems without the additional complexity that Anthropic is proposing in their post. Skills achieve the same progressive disclosure Anthropic describes, but without needing MCP as the underlying protocol. To circle back to my Firebase and GitHub MCP examples, the idea is that I could replace their MCPs with markdown files that explain how to correctly call their APIs or use their CLIs, and then I only need a single sentence to load those markdown files when using Firebase or GitHub. This means far fewer tokens and far less complexity.
Do We Need A Standard At All?
The only argument I truly see left for MCP is that if there’s many different AI agents, and many different external tools that AI agents will need to work with, it feels like there must be some reason we need to standardize that communication. But, protocols were created to help machines that understood neither English nor unstructured data by creating a highly structured machine format for them to parse. AI agents are excellent at understanding both English and unstructured data, raising the question of whether protocols even make sense in this new world.
Even if we imagine a world where Claude has a marketplace for third-party tools, if LLMs can now reliably call API specs, then MCP feels like it’s unnecessarily re-inventing OpenAPI’s wheel.
Ironically, Claude Skills seems like the more “AI-native” approach to LLMs using third party skills, but Skills is not an open standard. However, the underlying concept of a sentence that “points” to a larger set of prompts seems simple enough that it’s likely we see broader adoption of the concept if not Claude’s exact version. If anything, Mario’s blog post above indicates that people were hand-rolling their own version of Skills even before Anthropic formalized the concept.
But let’s finally note Anthropic created Claude and Claude Code, so they have some pretty smart and talented people. When they’ve invested massive amounts of time and resources into formalizing a standard like MCP, it’s possible they have insight and foresight that the broader developer community lacks. If not, MCP risks going down as a major blunder in a company that until now has seemed to be untouchable.