

Devs Cancel Claude Code En Masse - But Why?
Redditors have started a mass cancellation campaign of Anthropic's Claude Code over pricing and quality issues.

Claude Code has gone from developer darling to facing a mass cancellation campaign in the blink of an eye. The top post on Anthropic’s subreddit last week was Claude Is Dead with over 841 upvotes, over double the amount that Anthropic’s official response got.
Meanwhile, metrics from the Vibe Kanban - a tool which orchestrates AI agents - has shown Claude Code usage drop from 83% to 70%, with OpenAI’s Codex agent taking up slack (and taking most of Google’s Gemini agent’s usage along with it).
In this edition of AI Engineering Report, I’ll cover:
The reasons devs and Redditors have started a mass cancellation campaign for Claude Code
What AI agent benchmarks are saying about how AI coding agents compare
What this means for the AI coding agent landscape
Why Devs Are Canceling Claude Code En Masse
There are two reasons that this cancellation campaign started:
The first reason is usage limit changes. Anthropic announced that starting August 28, 2025, they added weekly usage limits across all Claude Pro and Max plans. These new limits now act alongside the existing 5-hour reset window, introducing an additional layer of restrictions.
Before (pre-Aug 28, 2025):
Only 5-hour rolling reset windows.
Pro: ~45 msgs / 5h.
Max $100: ~225 msgs / 5h.
Max $200: ~900 msgs / 5h.
No weekly caps.
After (post-Aug 28, 2025):
Still 5-hour reset windows, plus new weekly caps.
Pro: ~40–80 hrs Sonnet 4 / week (no Opus).
Max $100: ~140–280 hrs Sonnet 4 + ~15–35 hrs Opus / week.
Max $200: ~240–480 hrs Sonnet 4 + ~24–40 hrs Opus / week.
As a result, many users have hit rate limits that have made it difficult to complete their tasks despite paying $200 a month.
Perceived Quality Issues and Benchmarks
The second reason is perceived quality issues. Many Redditors have complained that they feel Claude Code is producing worse outputs. Some go on to theorize that Anthropic has degraded the model in an effort to reduce costs, such as by quantizing the model, or reducing the numerical precision which slightly degrades performance but massively saves on cost.
Many are switching to OpenAI Codex as their preferred alternatives. Here’s some top comments mentioned:
Claude → better for rapid prototyping, creative fill-in, mimicking style.
Codex → better for structured, step-controlled builds.
I use both. BUT when considering to go to the Pro plan on Claude vs OpenAI, I went with OpenAI. I dont trust Claude not to just crash or further downgrade/limit access. (source)
I find codex is better with writing the minimum code required to get the job done (source)
Most damning of all is the deep analysis of YouTuber GosuCoder who did a deep dive on AI agent performance using his custom benchmark suite you can learn more about at GosuEvals.
In his video, he summarizes his benchmark system as follows:
Instruction Following
Unit Tests
LLM as judge
While GosuCoder clearly spends an incredible amount of time evaluating AI agents, it’s important to note that his eval framework is not open source so that it can’t be gamed by AI agent creators. While his motivation makes sense, it does make it harder to evaluate the quality of his benchmarks.
Claude Code At The Bottom
Regardless of the quality of GosuCoder’s benchmarking system, it was shocking to find Claude Code toward the bottom of the pack.
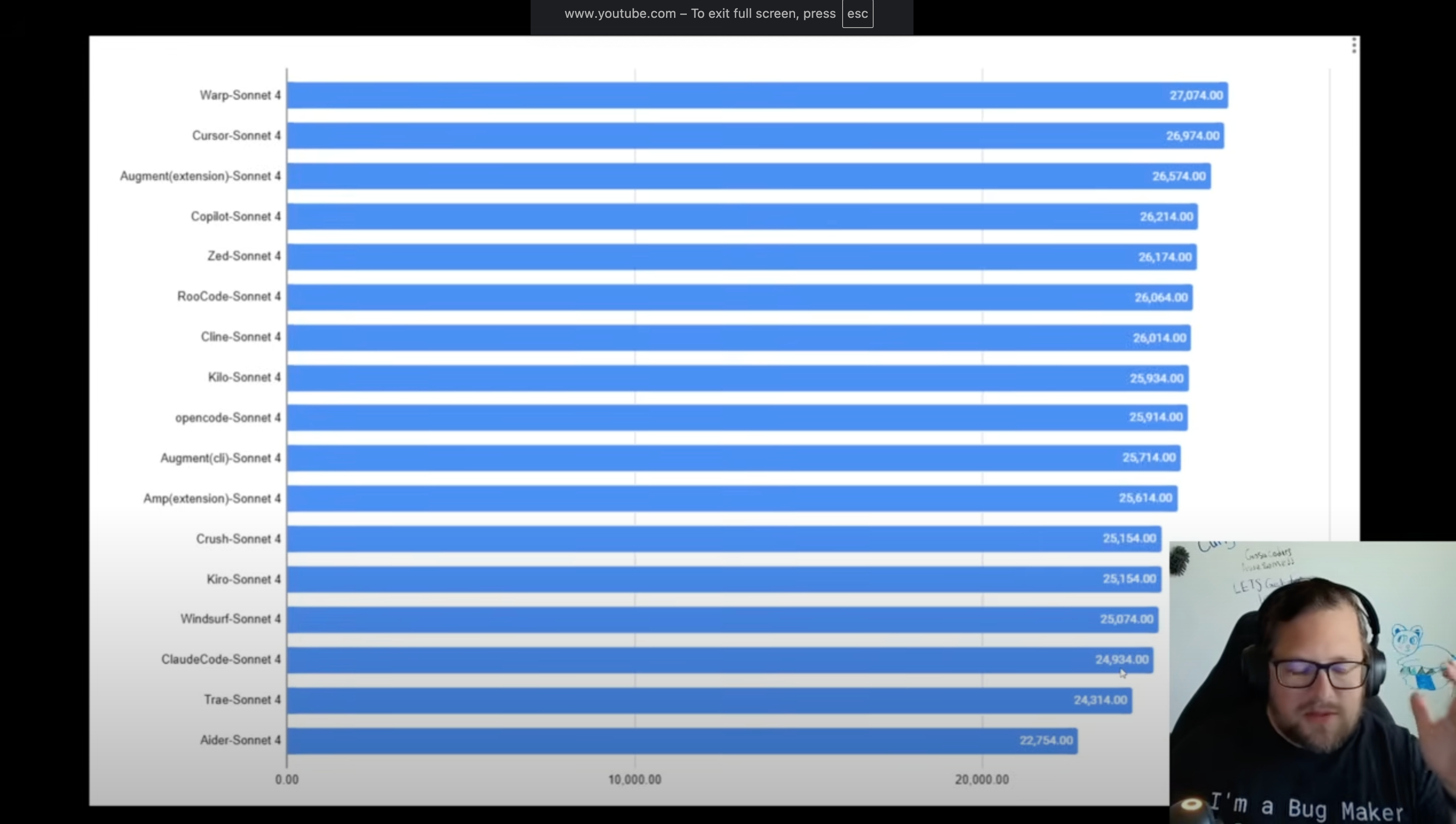
GosuCoder added the following commentary:
This is the thing that blows my mind….claude code used to be one of the better ones, and it has actually come down to be 24,314 now, it’s behind Kiro and Windsurf and Crush, and part of me wonders if comes with the nature of them trying to preserve tokens…or if the other agents have just caught up. Regardless Claude Code is still incredibly good value, but it’s surprising to me how much it’s fallen.
Anthropic Responds
Anthropic took to their own subreddit to make an official statement on perceived quality degradation performance. They admitted known bugs had hurt performance for some users but denied intentionally degrading performance to handle cost.
We've received reports, including from this community, that Claude and Claude Code users have been experiencing inconsistent responses. We shared your feedback with our teams, and last week we opened investigations into a number of bugs causing degraded output quality on several of our models for some users. Two bugs have been resolved, and we are continuing to monitor for any ongoing quality issues, including investigating reports of degradation for Claude Opus 4.1.
Implications and My Take
Let’s state the obvious - Redditors like to overdramatize things and vocal minorities often seem bigger than they are, with some stating that Claude Code is still easily the best. Many commenters still preferred Claude Code to Codex, and even the ones who do prefer Codex described the CLI as poor and suggested a separate repo to fix the UX issues.
Furthermore, GosuCoder’s benchmarks were shown as “proof” that quality degraded despite not being open to public scrutiny, still being subjective (as all benchmarks are), and perhaps most importantly, Claude Code was only 10% behind the leader in his scoring system. That type of difference could easily be changed by a tweak to the scoring system.
In my own experience, benchmarking AI agents is incredibly difficult. Most of them are quite good at accomplishing well-defined tasks and struggle at novel tasks or tasks they lack good training examples on. This often makes them more similar than different. Furthermore, they are often more influenced by prompting strategies and context provided than by the difference in the agent quality themselves. Finally, “good code” has always been somewhat subjective, so evaluations of AI coding “quality” is likewise subjective.
Even by the “stats” proving the demise of Claude Code, we can see that it dropped from 83% to 70% on the Vibe Kanban tool (and it’s unclear how reflective that is of broader industry trends), which is still the market leader. Still, Anthropic issuing an official response does indicate they were at least somewhat concerned by the accusations and wanted to quell them, with many end-users appreciating Anthropic’s transparency on the issue.
Thanks for reading AI Engineering Report, please reply by email or leave a Substack comment if you have any opinions on this topic!
I was on Claude Code MAX 100$ subscription, cancelled yesterday.
This was not a punctual drop in quality, I have been experiencing consistent bad quality in the past 2 weeks, while my prompting practice hasn't changed. I used to be amazed by Claude Code output, and while it has always been the case that if used wrong, it could go wild, but recently answers where bad on the most basic tasks. I pulled the trigger when it started failing on a simple python pandas filtering.
I'm using it to write roblox Lua scripts. Claude was doing great till lately when it edits, it does it correctly but then deletes the corrected code and says it fixed it but it have deleted that part and rewrited back to wrong code. Usually writing new code from scratch fixes it but it eats my allowance. After 3 months cancelled my pro plan.