

Claude Code vs Codex: I Built A Sentiment Dashboard From 500+ Reddit Comments
I scraped hundreds of Reddit comments that compare Claude Code and Codex, and used Claude Haiku to build a sentiment analysis dashboard. The dashboard and my interpretations are shared here.

Most benchmarks tell us how AI coding models perform in carefully constructed scenarios. But they don’t tell us what developers actually think when they use these tools every day. That gap is why I built a Reddit sentiment analysis dashboard to see how real engineers compare Claude Code vs Codex in the wild. You can find the dashboard at
https://claude-vs-codex-dashboard.vercel.app/
and the source code at: https://github.com/waprin/claude-vs-codex-dashboard
There are some options to view sentiment weighted or unweighted by upvotes, and compare on specific categories like speed, problem solving, and workflows.
In this newsletter edition, I’ll discuss:
What trends the sentiment analysis dashboard uncovers on Claude Code vs Codex discussions on Reddit
The methodology I used to build the dashboard and plans for future improvements
While notable AI benchmarks like SWEbench, PR Arena, TerminalBench, and LMArena help us navigate the landscape of the quality of AI models, I don’t think any benchmark can truly capture how most software engineers are using agentic coding models day-to-day. We don’t typically “set-it-and-forget” the agent on a constructed task but rather there’s an interactive back-and-forth conversational session. Furthermore, engineers in the wild are facing a far greater diversity of tasks than any given benchmark could hope to capture.
For those reasons, I believe a survey of the “wisdom of the crowd” is valuable to gain a broader understanding of which agentic coding models are performing better. To do so, I scraped a wide variety of comments on Reddit from AI-coding focused subreddits such as /r/ChatGPTCoding, /r/ClaudeCode, and /r/Codex. I then used the Claude Haiku model to classify whether the comment directly compared Claude Code and Codex, and classified the sentiment accordingly.
(note: this analysis was done before the new Haiku model that Anthropic announced yesterday)
Since this post is fairly long, I’ll summarize here:
Overall, Codex has much more positive sentiment than Claude Code in comments that compare the two directly
However, Claude Code has much more discussion overall, at about 4x the volume of Codex, raising the question of whether its popularity leads to its detractors
On specific topics like performance, model quality, and problem-solving, Codex leads in all categories except two - speed and workflows. Claude Code is considered faster to respond and has a better terminal UX and ecosystem of tools. Codex frequently gets complimented for outperforming Claude Code on more challenging problems.
Claude Code performing better on speed but Codex on problem-solving also aligns with some tweets I’ve seen in the wild.
Let’s dive into some specific takeaways, and then I’ll circle back to my notes on the methodology.
Codex Wins the Sentiment War By A Large Margin
The first takeaway is that Codex is compared more positively against Claude Code by a fairly large margin:
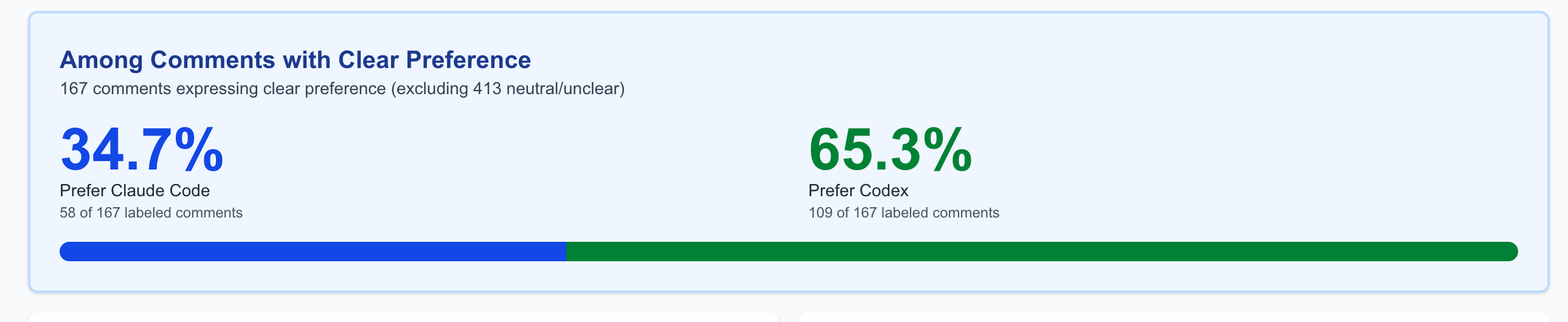
As you can see, 65.3% of Reddit comments comparing Claude Code vs Codex prefer Codex.
The above metric only tallies raw number of comments. If we weight those comments by upvotes, so a comment with 10 upvotes counts ten times as much as a comment with 1 upvote, the sentiment difference is even more stark.
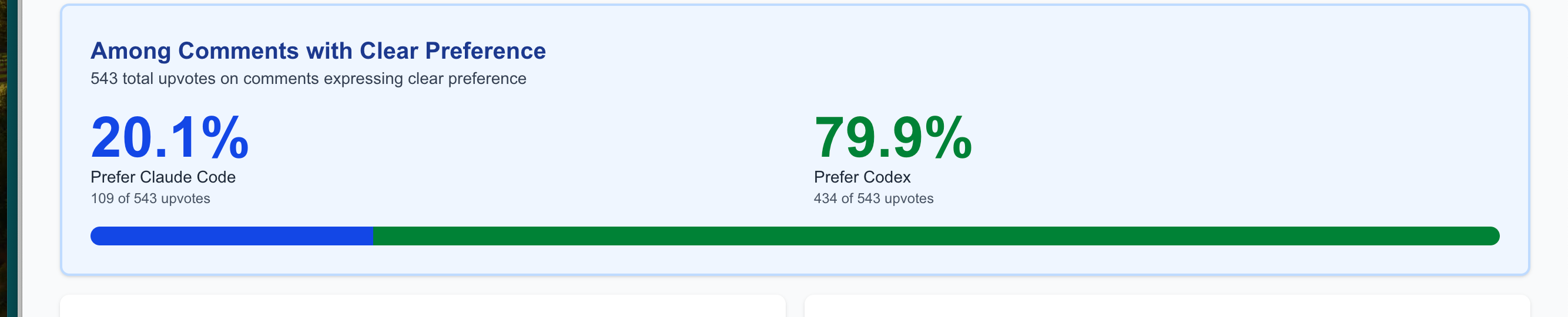
We can see that 79.9% of Reddit upvotes prefer Codex to Claude Code.
The dashboard also lets you see all the Reddit comments at the bottom, sorted by upvotes and optionally filtered by themes such as speed or price, if you want to see the original comments.
But People Are Talking About Claude Code Much More….And Reddit Is A Negative Place
While Codex has far more positive sentiment than Claude Code, it’s worth noting that people are simply talking about Claude Code significantly more than Codex.
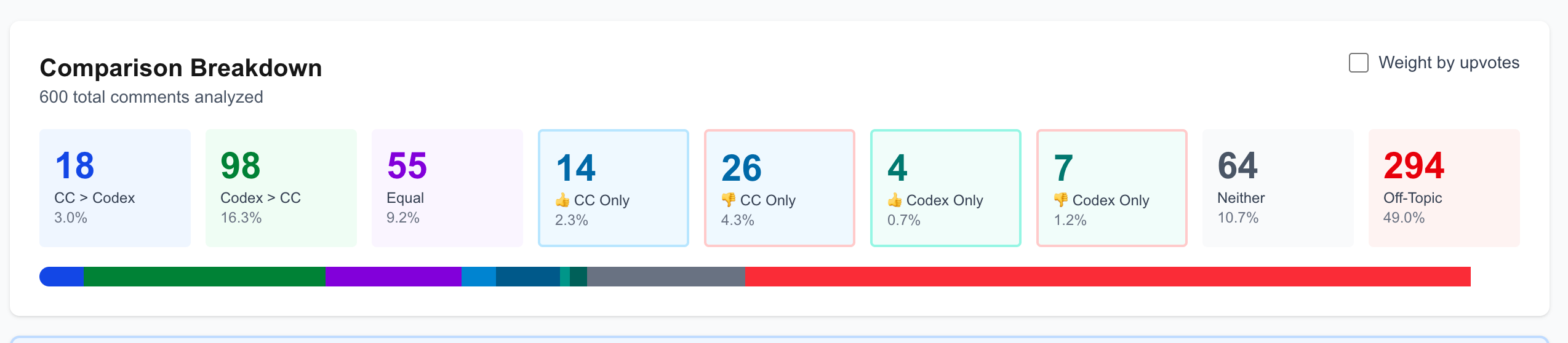
As you can see, “Codex>CC” has 98 comments vs. 18 comments that have “CC>Codex”. But if we look at comments that don’t directly compare the tools, both Claude Code and Codex have more negative comments than positive comments. People tend to complain more than praise on the internet. But of the 500 comments, Claude Code had 40 comments and Codex only had 10. This means people are talking about Claude Code about four times as much as they’re talking about Codex.
You can also see the volume of Claude Code discussion evidenced by the subreddits themselves, with /r/ClaudeCode having 4.2k weekly contributions and /r/codex having 1.2k weekly contributions.
This raises the question of how much negativity towards Claude Code is because the most popular tool tends to get the most criticism.
GLM As A New Dark Horse
I was surprised to see extensive discussion comparing Claude Code and Codex to another competitor I never even heard of, GLM, a Chinese agentic coding agent. In fact, one of the top threads in /r/ClaudeCode recently is: Why I Finally Quit Claude (and Claude Code) for GLM, with the top comment reading:
GLM surprised me when I tried it recently. It’s not as good (yet) in terms of agentic capabilities compared to Codex or Claude, but it’s good enough it produces quality results for pennies on the dollar in terms of cost. Easily the best value LLM around right now.
Top Comment in Favor of Claude Code
i‘ve been testing sonnet 4.5, gpt5-codex and glm 4.6 plans over the past few days with a nextjs project.
i think sonnet 4.5 is easily the best of the bunch. glm 4.6 is the worst, it needs a really good plan by a sota model or well broken down tasks, otherwise it codes itself in a corner.
gpt5 codex is great, sometimes best but i hit the limits much quicker than sonnet 4.5, even after the anthropic rate limit changes a few days ago. that’s on the 20$ plan. i also like claude code much more and the surrounding ecosystem of tools.— User serialoverflow (source)
Top Comment in Favor Of Codex
Former Claude Code user for a few months on Max 20x, fairly heavy user too. Loved it at the time, but feels like at least during part of last month the quality of the model responses degraded. I found myself having to regularly steer Claude into not making changes I didn’t actually agree on (yes I use the plan mode, it’s highly valuable). Claude also often told me that code was production ready when it wasn’t, it either failed to compile or had some kind of flaw that needed addressing.
The biggest challenge I’ve given it so far was to refactor a long overdue and messy .cs file that contained about 3k LOC. I’ve tried this with various other AI LLMs, including Claude Code (which couldn’t read the entire file as it was over 25k tokens), but they just ultimately make bugs and mess things up when trying to do so. I didn’t think GPT-5 would be any different, but my god, it surprised me again. I planned with it, did it in small bits and pieces at a time, and a day or so later I’m now down to around 1k LOC for that file. It seems to be working fine too.
— User Hauven (source)
Claude Beats Codex On Two Categories - Speed and Workflows. Codex won the rest.
The dashboard allows you to filter by specific topics, and Codex leads Claude Code on 8 of 10 categories. However, Claude Code leads on two - speed and workflows. This aligns with much of the discussion I’ve seen online, where people generally think Codex is a stronger model but notice that Claude Code just returns a response faster and that the terminal UX and tool ecosystem is stronger.
Codex won the rest of the categories: pricing, performance, reliability, usage limits, code generation, problem solving, and code quality.
Notes On Methodology - Data Collection Via Scraping Reddit
To decide which Reddit comments to even scrape, I first used Google Search with the query `site:reddit.com “claude code” codex`. The vast majority of the results were from Claude-related subreddits - namely /r/ClaudeCode , /r/ClaudeAI, and /r/Anthropic. The only other subreddit with a large number of results is /r/ChatGPTCoding, which despite its name, is geared towards any sort of AI-coding discussion and is not ChatGPT specific.
Some other subreddits such as /r/Cursor, /r/OpenAI, /r/LLMDevs, /r/vibecoding, /r/AI_Agents, etc had a small number of results but were not significant.
Given that the Google Search API is severely limited in the number of results you can return, and the Bing API is being deprecated, the simplest way to scrape these comments is to use the Reddit API.
I focused on /r/ClaudeCode, /r/ChatGPTCoding, and /r/Codex. However, while I have some /r/Codex comments, none of them made it into this first analysis pass. I decided not to include /r/ClaudeAI despite a significant amount of discussion there because the dataset was already heavily biased towards Claude-centric discussions.
Notes On Methodology - Sentiment Analysis Time And Cost With Claude Haiku
I decided to use Claude Haiku to analyze the sentiment on each comment. I did make sure that each comment had its entire parent chain within its context when doing the sentiment analysis. This is important context if a comment says something like “I agree”.
I was curious if I should save time and cost by batching comments, but Claude itself recommended against this approach and suggested it could too easily distort results. There are actually two ways to consider batching here. We could batch by asking it to rate multiple comments at a time, which I decided against and there’s the Batch processing Anthropic API, which I didn’t get around to using yet but might add in the future to save time.
I did use Haiku since it’s one of the cheaper models. Overall, the cost was not an issue, but the time took surprisingly long. For some data points:
50 comments took 3 minutes, 28k input tokens, 10k output tokens, and $0.08 to analyze.
500 comments took 26.7 minutes, 273k input tokens, and $0.77 to analyze
As you can see, even fairly big batches cost under $1 to analyze, but waiting 25 minutes for the results was slightly annoying.
Haiku may have been slighty overkill, as Gemini Flash may have been cheaper, but Haiku was cheap enough as-is.
Takeaways And Conclusions
Again, check out the link to the dashboard at the top of the post or the GitHub repo if you’re curious to dig in yourself.
On a personal note, I’ve played with Codex but have been finding myself using Claude Code more because speed makes programming more fun for me, and having fun means I stick to the work longer. But I am exploring how to upskill my agentic coding with background agents and spec-driven development, and it’s very clear that the broader community sentiment suggests Codex is a stronger tool here than Claude Code.
Let me know if you’re interested in this topic by replying to this email or leaving a comment on Substack. I plan to add more comments to the analysis, and I’m also interested in comparing the sentiment analysis result of Haiku vs stronger models like GPT-5 or Sonnet and see if any differences emerge. Thanks for reading!
Super interesting! I had never heard of GLM either. I've been a Claude Code loyalist, but this makes me think I should give Codex another shot.
Also a very cool analysis; this could be a product in itself (input {2+} things & in an hour you'll get an email with a link to a Reddit sentiment comparison dashboard with key quotes).